业务背景
-
新站迁移后,页面的链接发生改变,要求访问老链接时自动跳转至新链接 访问产品页、类目页、CMS页等页面时,如果访问老链接,需要自动跳转至新链接,由于这些页面全部是流量非常大的页面,所以需要将老链接=>新链接的缓存缓存起来以加快速度并降低MySQL的负载。起初我的做法很简单: ①如果老链接=>新链接的对应关系存在,则将query_url => redirect_url缓存起来 ②如果老链接=>新链接的对应关系不存在,为防止缓存击穿,将query_url => “” 缓存起来 虽然可以正常工作,但是由于query_url几乎是无限的,导致redis里的key的数量不断上升 那能不能很快地知道某个query_url是不是老链接呢?
-
偏远地区运费计算 一直以来,我们将运输方式分为三个等级:普通、快、特快,运费按等级收取,但是快递公司对一些偏远地区要加收额外的偏远运费。对于发货地址是偏远地区的订单,需要额外收取偏远地区运费。 运营人员将偏远地区的邮编、运费整理出一个表格,如果用户提交的邮编,命中这些邮编时,则收取额外运费。我初步计算文档内数据量在20万条左右,如果每次计算订单金额时都要在MySQL中查询偏远地区运费,必然会拖慢订单金额计算速度,毕竟大部分订单的发货地址都不是偏远地区。 那能不能很快的知道某个邮编在不在这些偏远地区邮编里呢?
对于上面两个问题,前辈们早已想出了一个很好的解决方案: 布隆过滤器(Bloom Filter)
布隆过滤器基本概念
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(log n),O(1)。
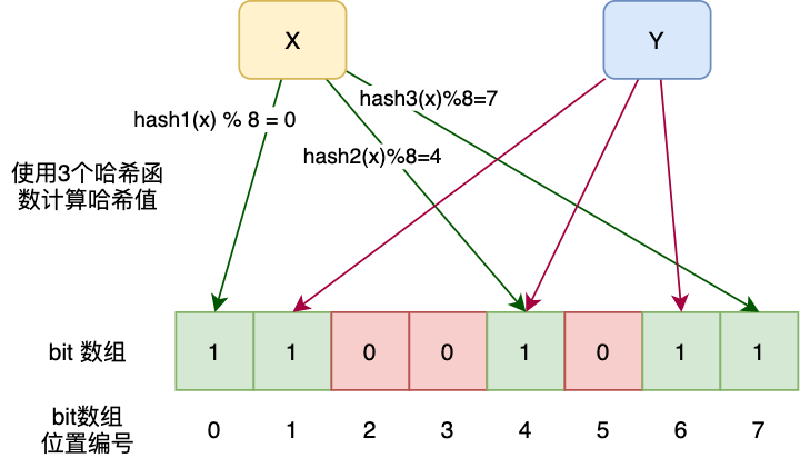
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(O(k))。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。另外,一般情况下不能从布隆过滤器中删除元素。
代码实现思路:
- 保存和获取: 基于 Redis 的 SETBIT 和 GETBIT 两个命令实现
- Hash函数: 参考链接 https://www.partow.net/programming/hashfunctions/
- 初始化: 对于大量的记录,如果要通过 Redis 的 SETBIT 命令进行录入,会非常耗时,在我的开发机器上测试,写入10万条记录需要大约40秒,所以在初始化时需要另寻他法。幸好 Redis 的 bitmap 是基于 Redis String 数据类型实现的,所以先将二进制数据转换为字符串,再一次性写入 Redis,速度非常快
- 控制 Redis bitmap 的大小: 如果对Hash函数计算得出的offset不做转换,那每一个布隆过滤器的bitmap实际占用内存会非常大,因为offset可能是一个非常大的整数,例如offset=2^30,为了保存第2^30个bit上的1, Redis最少需要开辟2^30 bit(128 MB)的内存空间。那么如何限制布隆过滤器的bitmap的实际大小呢?只要限制offset的大小即可,初始化BloomFilter对象时,指定bitMapSize,然后对每个offset按bitMapSize取余,这样就能保证所有的offset都小于bitMapSize,也就将布隆过滤器的bitmap实际大小控制在了bitMapSize bits。
- 控制误判率:设共存入n个元素,每个元素取3个hash,则极限误判率 = (n * 3 / bitMapSize)^3 (假设存入的每个元素,hash均不发生碰撞)。 例如存入100万个元素,bitMapSize设置为 1MB, 极限误判率 = (3000000/(1024 * 1024 * 8))^3 = 4.57%, 由于存入元素时,hash可能会碰撞(碰撞率我猜测可能符合正态分布),所以一般情况下的误判率为极限误判率的60%。
代码实现
以下是基于PHP的Yii2框架实现的一个简易布隆过滤器
|
|
误判率测试代码:
|
|